Насколько Forecast NOW! лучше модели Экспоненциального сглаживания (ES) вы можете увидеть на графике ниже. По оси X - номер товара, по оси Y - процентное улучшение качества прогноза. Описание модели, детальное исследование, результаты экспериментов читайте ниже.
Описание модели
Прогнозирование методом экспоненциального сглаживания является одним из самых простых способов прогнозирования. Прогноз может быть получен только на один период вперед. Если прогнозирование ведется в разрезе дней, то только на один день вперед, если недель, то на одну неделю.
Для сравнения прогнозирование проводилось на неделю вперед в течение 8 недель.
Что такое экспоненциально сглаживание?
Пусть ряд С представляет исходный ряд продаж для прогнозирования
С(1)- продажи в первую неделю, С (2) во второй и так далее.

Рисунок 1. Продажи по неделям, ряд С
Аналогично, ряд S представляет собой экспоненциально сглаженный ряд продаж. Коэффициент α находится от нуля до единицы. Получается он следующим образом, здесь t - момент времени (день, неделя)
S (t+1) = S(t) + α *(С(t) - S(t))
Большие значения константы сглаживания α ускоряют отклик прогноза на скачок наблюдаемого процесса, но могут привести к непредсказуемым выбросам, потому что сглаживание будет почти отсутствовать.
Первый раз после начала наблюдений, располагая лишь одним результатом наблюдений С (1) , когда прогноза S(1) нет и формулой (1) воспользоваться еще невозможно, в качестве прогноза S(2) следует взять С (1) .
Формула легко может быть переписана в ином виде:
S(t+1) = (1 - α)* S(t) + α * С(t) .
Таким образом, с увеличением константы сглаживания доля последних продаж увеличивается, а доля сглаженных предыдущих уменьшается.
Константа α выбирается опытным путем. Обычно строится несколько прогнозов для разных констант и выбирается наиболее оптимальная константа с точки зрения выбранного критерия.
Критерием может выступать точность прогнозирования на предыдущие периоды.
В своем исследовании мы рассмотрели модели экспоненциального сглаживания, в которых α принимает значения {0.2, 0.4, 0.6, 0.8}. Для сравнения с алгоритмом прогнозирования Forecast NOW! для каждого товара строились прогнозы при каждом α, выбирался наиболее точный прогноз. В действительности же, ситуация обстояла бы гораздо более сложная, пользователю не зная наперед точности прогноза нужно определиться с коэффициентом α, от которого очень сильно зависит качество прогноза. Вот такой замкнутый круг.
Наглядно

Рисунок 2. α =0.2 , степень экспоненциального сглаживания высокая, реальные продажи учитываются слабо

Рисунок 3. α =0.4 , степень экспоненциального сглаживания средняя, реальные продажи учитываются в средней степени
Можно видеть как с увеличением константы α сглаженный ряд все сильнее соответствует реальным продажам, и если там присутствуют выбросы или аномалии, мы получим крайне неточный прогноз.

Рисунок 4. α =0.6 , степень экспоненциального сглаживания низкая, реальные продажи учитываются значительно
Можем видеть, что при α=0.8 ряд почти в точности повторяет исходный, а значит прогноз стремится к правилу «будет продано столько же, сколько и вчера»
Стоит отметить, что здесь совершенно нельзя ориентироваться на ошибку приближения к исходным данным. Можно добиться идеального соответствия, но получить неприемлемый прогноз.

Рисунок 5. α =0.8 , степень экспоненциального сглаживания крайне низкая, реальные продажи учитываются сильно
Примеры прогнозов
Теперь давайте посмотрим на прогнозы, которые получаются с использованием различных значений α. Как можно видеть из рисунка 6 и 7, чем больше коэффициент сглаживания, тем точнее повторяет реальные продажи с опозданием на один шаг, прогноз. Такое опоздание на деле может оказаться критичным, поэтому нельзя просто выбирать максимальное значение α. Иначе получится ситуация, когда мы говорим, что будет продано ровно столько, сколько было продано в прошлый период.

Рисунок 6. Прогноз метода экспоненциального сглаживания при α=0.2

Рисунок 7. Прогноз метода экспоненциального сглаживания при α=0.6
Давайте посмотрим, что получается при α = 1.0. Напомним, S - прогнозируемые (сглаженные) продажи, C - реальные продажи.
S(t+1) = (1 - α)* S(t) + α * С(t) .
S(t+1) = С(t) .
Продажи в t+1 день согласно прогнозу равны продажам в предыдущий день. Поэтому к выбору константы надо подходить с умом.
Сравнение с Forecast NOW!
Теперь рассмотрим данный метод прогнозирования в сравнении с Forecast NOW!. Сравнение велось на 256 товарах, которые имеют различные продажи, с сезонностью краткосрочной и долгосрочной, с «плохими» продажами и дефицитом, акциями и прочими выбросами. Для каждого товара был построен прогноз по модели экспоненциального сглаживания, для различных α, выбирался лучший и сравнивался с прогнозом по модели Forecast NOW!
В таблице ниже вы видите значение ошибки прогноза для каждого товара. Ошибка здесь считалась как RMSE. Это корень из среднеквадратичного отклонения прогноза от реальности. Грубо говоря, показывает, на сколько единиц товара мы отклонились в прогнозе. Улучшение показывает, на сколько процентов прогноз Forecast NOW! лучше, если цифра положительная, и хуже, если отрицательная. На рисунке 8 по оси X отложены товары, по оси Y указано насколько прогноз Forecast NOW! лучше, чем прогнозирование методом экспоненциального сглаживания. Как можно видеть из этого графика, точность прогнозирования Forecast NOW! почти всегда в два раза выше и почти никогда не хуже. На деле это означает, что использование Forecast NOW! позволит в два раза сократить запасы или снизить дефицит.
Сервис позволит провести сглаживание временного ряда y t экспоненциальным методом, т.е. простроить модель Брауна (см. пример).
Инструкция . Укажите количество данных (количество строк), нажмите Далее. Полученное решение сохраняется в файле Word .
Особенность метода экспоненциального сглаживания заключается в том, что в процедуре нахождения сглаженного уровня используются значения только предшествующих уровней ряда, взятые с определенным весом, причем вес уменьшается по мере удаления его от момента времени, для которого определяется сглаженное значение уровня ряда. Если для исходного временного ряда y 1 , y 2 , y 3 ,…, y n соответствующие сглаженные значения уровней обозначить через S t , t = 1,2,...,n , то экспоненциальное сглаживание осуществляется по формуле:S t = (1-α)yt + αS t-1
В некоторых источниках приводится другая формула:
S t = αyt + (1-α)S t-1
Где α - параметр сглаживания (0 В практических задачах обработки экономических временных рядов рекомендуется (необоснованно) выбирать величину параметра сглаживания в интервале от 0.1 до 0.3 . Других точных рекомендаций для выбора оптимальной величины параметра α пока нет. В отдельных случаях предлагается определять величину α исходя их длины сглаживаемого ряда: α = 2/(n+1).
Что касается начального параметра S 0 , то в задачах его берут или равным значению первого уровня ряда у 1 , или равным средней арифметической нескольких первых членов ряда.
Если при подходе к правому концу временного ряда сглаженные этим методом значения при выбранном параметре α начинают значительно отличаться от соответствующих значений исходного ряда, необходимо перейти на другой параметр сглаживания. Достоинством этого метода является то, что при сглаживании не теряются ни начальные, ни конечные уровни сглаживаемого временного ряда.
Сглаживание экспоненциальным методом в Excel
Для вычисления каждого прогноза MS Excel использует отдельную, но алгебраически эквивалентную формулу. Оба компонента – данные предыдущего наблюдения и предыдущий прогноз – каждого прогноза умножаются на коэффициент, отображающий вклад данного компонента в текущий прогноз.Активизировать средство Экспоненциальное сглаживание можно, выбрав команду Сервис/Анализ данных после загрузки надстройки Пакет анализа ().
Пример
. Проверить ряд на наличие выбросов методом Ирвина, сгладить методом экспоненциального сглаживания (α = 0.1).
В качестве S 0 берем среднее арифметическое первых 3 значения ряда.
S 0 = (50 + 56 + 46)/3 = 50.67
| t | y | S t | Формула |
| 1 | 50 | 50.07 | (1 - 0.1)*50 + 0.1*50.67 |
| 2 | 56 | 55.41 | (1 - 0.1)*56 + 0.1*50.07 |
| 3 | 46 | 46.94 | (1 - 0.1)*46 + 0.1*55.41 |
| 4 | 48 | 47.89 | (1 - 0.1)*48 + 0.1*46.94 |
| 5 | 49 | 48.89 | (1 - 0.1)*49 + 0.1*47.89 |
| 6 | 46 | 46.29 | (1 - 0.1)*46 + 0.1*48.89 |
| 7 | 48 | 47.83 | (1 - 0.1)*48 + 0.1*46.29 |
| 8 | 47 | 47.08 | (1 - 0.1)*47 + 0.1*47.83 |
| 9 | 47 | 47.01 | (1 - 0.1)*47 + 0.1*47.08 |
| 10 | 49 | 48.8 | (1 - 0.1)*49 + 0.1*47.01 |
Простая и логически ясная модель временного ряда имеет следующий вид:
Y t = b + e t
у, = Ь + г„ (11.5)
где b - константа, e - случайная ошибка. Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения значения b из данных состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред- предпоследним, и т.д. Простое экспоненциальное сглаживание именно так и построено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не только те, которые попали в определенное окно. Точная формула простого экспоненциального сглаживания имеет вид:
S t = a y t + (1 - a) S t -1
Когда эта формула применяется рекурсивно, каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра a. Если a равен 1, то предыдущие наблюдения полностью игнорируются. Если aравен 0, то игнорируются текущие наблюдения. Значения a между 0 и 1 дают промежуточные результаты. Эмпирические исследования показали, что простое экспоненциальное сглаживание весьма часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать a меньше 0,30. Однако выбор a больше 0,30 иногда дает более точный прогноз. Это значит, что лучше все же оценивать оптимальное значение a по реальным данным, чем использовать общие рекомендации.
На практике оптимальный параметр сглаживания часто ищется с использованием процедуры поиска на сетке. Возможный диапазон значений параметра разбивается сеткой с определенным шагом. Например, рассматривается сетка значений от a = 0,1 до a = 0,9 с шагом 0,1. Затем выбирается такое значение a, для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
Microsoft Excel располагает функцией Exponential Smoothing (Экспоненциальное сглаживание), которая обычно используется для сглаживания уровней эмпирической временного ряда на основе метода простого экспоненциального сглаживания. Для вызова этой функции необходимо на панели меню выбрать команду Tools Þ Data Analysis. На экране раскроется окно Data Analysis, в котором следует выбрать значение Exponential Smoothing (Экспоненциальное сглаживание). В результате появится диалоговое окно Exponential Smoothing.
В диалоговом окне Exponential Smoothing задаются практически те же параметры, что и в рассмотренном выше диалоговом окне Moving Average.
1. Input Range (Входные данные) - в это поле вводится диапазон ячеек, содержащих значения исследуемого параметра.
2. Labels (Метки) - данный флажок опции устанавливается в том случае, если
первая строка (столбец) во входном диапазоне содержит заголовок. Если заголовок отсутствует, флажок следует сбросить. В этом случае для данных выходного диапазона будут автоматически созданы стандартные названия.
3. Damping factor (Фактор затухания) - в это поле вводится значение выбранного коэффициента экспоненциального сглаживания а. По умолчанию принимаете значение а = 0,3.
4. Output options (Параметры вывода) - в этой группе, помимо указания диапазона ячеек для выходных данных в поле Output Range (Выходной диапазон), можно также потребовать автоматически построить график, для чего необходимо установить флажок опции Chart Output (Вывод графика), и рассчитать стандартные погрешности, для чего нужно установить флажок опции Standart Erroг (Стандартные погрешности).
Задание 2. С помощью программы Microsoft Excel, используя функцию Экспоненциального сглаживания (Exponential Smoothing), на основании данных об объеме выпуска Задания 1 рассчитать сглаженные уровни выпуска и стандартные погрешности. Затем представить фактические и прогнозируемые данные с помощью диаграммы. Подсказка: должна получиться таблица и график, аналогичный выполненному в задание 1, но с другими сглаженными уровнями и стандартными погрешностями.
Метод аналитического выравнивания
где - теоретические значения временного ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t.
Определение теоретических (расчетных) значений , производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает основную тенденцию развития временного ряда.
Простейшими моделями (формулами), выражающими тенденцию развития, являются следующие:
Линейная функция, график которой является прямой линией:
Показательная функция:
Y t = a 0 * a 1 t
Степенная функция второго порядка, график которой является параболой:
Y t = a 0 + a 1 * t + a 2 * t 2
Логарифмическая функция:
Y t = a 0 + a 1 * ln t
Расчет параметров функции обычно производится методом наименьших квадратов, в котором в качестве решения принимается точка минимума суммы квадратов отклонений между теоретическим и эмпирическим уровнями:
![]()
где - выровненные (расчетные) уровни, а Yt - фактические уровни.
Параметры уравнения a i удовлетворяющие этому условию, могут быть найдены решением системы нормальных уравнений. На основе найденного уравнения тренда вычисляются выровненные уровни.
Выравнивание по прямой используется в тех случаях, когда абсолютные приросты практически постоянны, т.е. когда уровни изменяются в арифметической прогрессии (или близко к ней).
Выравнивание по показательной функции применяется, когда ряд отражает развитие в геометрической профессии, т.е. цепные коэффициенты роста практически постоянны.
Выравнивание по степенной функции (параболе второго порядка) используется, когда ряды динамики изменяются с постоянными цепными темпами прироста.
Выравнивание по логарифмической функции применяется, когда ряд отражает развитие с замедлением роста в конце периода, т.е. когда прирост в конечных уровнях временного ряда стремится к нулю.
По вычисленным параметрам выполняется синтез трендовой модели функции, т.е. получение значений a 0 , a 1 , a ,2 и их подстановка в искомое уравнение.
Правильность расчетов аналитических уровней можно проверить по следующему условию: сумма значений эмпирического ряда должна совпадать с суммой вычисленных уровней выровненного ряда. При этом может возникнуть небольшая погрешность в расчетах из-за округления вычисляемых величин:
Для оценки точности трендовой модели используется коэффициент детерминации:

где - дисперсия теоретических данных, полученных по трендовой модели, а - дисперсия эмпирических данных.
Трендовая модель адекватна изучаемому процессу и отражает тенденцию его развития при значениях R 2 , близких к 1.
После выбора наиболее адекватной модели можно сделать прогноз на любой из периодов. При составлении прогнозов оперируют не точечной, а интервальной оценкой, определяя так называемые доверительные интервалы прогноза. Величина доверительного интервала определяется в общем виде следующим образом:

где среднее квадратическое отклонение от тренда; t a - табличное значение t- критерия Стьюдента при уровне значимости a , которое зависит от уровня значимостиa (%) и числа степеней свободы к = п - т. Величина - определяется по формуле:

где и – фактические и расчетные значения уровней динамического ряда; п - число уровней ряда; т - количество параметров в уравнении тренда (для уравнения прямой т - 2, для уравнения параболы 2-го порядка т = 3).
После необходимых расчетов определяется интервал, в котором с определенной вероятностью будет находиться прогнозируемая величина.
С помощью Microsoft Excel строить трендовые модели достаточно просто. Сначала эмпирический временной ряд следует представить в виде диаграммы одного из следующих типов: гистограмма, линейчатая диаграмма, график, точечная диаграмма, диаграмма с областями, а затем щелкнуть на диаграмме правой кнопкой мыши на одном из маркеров данных. В результате на диаграмме будет выделен сам временной ряд, а на экране раскроется контекстное меню. В этом меню следует выбрать команду Add Trendline (Добавить линию тренда). На экран будет выведено диалоговое окно Add Trendline.
На вкладке Туре (Тип) этого диалогового окна выбирается требуемый тип тренда:
1. линейный (Linear);
2. логарифмический (Logarithmic);
3. полиномиальный, от 2-й до 6-й степени включительно (Polinomial);
4. степенной (Power);
5. экспоненциальный (Exponential);
6. скользящее среднее, с указанием периода сглаживания от 2 до 15 (Moving Average).
На вкладке Options (Параметры) этого диалогового окна задаются дополнительные параметры тренда.
1. Trendline Name (Название сглаженной кривой) - в этой группе выбирается название, которое будет выведено на диаграмму для обозначения функции, использованной для сглаживания временного ряда. Возможны следующие варианты:
♦ Automatic (Автоматическое) - при установке переключателя в это положение Microsoft Excel автоматически формирует название функции сглаживания тренда, основываясь на выбранном типе тренда, например Linear (Линейная функция).
♦ Custom (Другое) - при установке переключателя в данное положение в поле справа можно ввести собственное название для функции тренда, длиной до 256 символов.
2. Forecast (Прогноз) - в этой группе можно указать, на сколько периодов вперед (поле Forward) требуется спроектировать линию тренда в будущее и на сколько периодов назад (поле Backward) следует спроектировать линию тренда в прошлое (эти поля недоступны в режиме скользящего среднего).
3. Set intercept (Пересечение кривой с осью Y в точке) - этот флажок опции и расположенное справа поле ввода позволяют непосредственно указать точку, в которой линия тренда должна пересекать ось Y (эти поля доступны не для всех режимов).
4. Display equation on chart (Показывать уравнение на диаграмме) - при установке этого флажка опции на диаграмму будет выведено уравнение, описывающее сглаживающую линию тренда.
5. Display R-squared value on chart (Поместить на диаграмму величину достоверности аппроксимации R 2) - при установке данного флажка опции на диаграмме будет показано значение коэффициента детерминации.
Вместе с линией тренда на графике временного ряда могут быть также изображены планки погрешностей. Для вставки планок погрешностей необходимо выделить ряд данных, щелкнуть на нем правой кнопкой мыши и выбрать в раскрывшемся контекстном меню команду Format Data Series. На экране раскроется диалоговое окно Format Data Series (Формат ряда данных), в котором следует перейти на вкладку Y Error Bars (Y-погрешности).
На этой вкладке с помощью переключателя Error amount (Величина погрешности) выбирается тип планок и вариант их расчета в зависимости от вида погрешности.
1. Fixed value (Фиксированное значение) - при установке переключателя в это положение за допустимую величину ошибки принимается заданное в поле счетчика справа постоянное значение;
2. Percentage (Относительное значение) - при установке переключателя в данное положение для каждой точки данных вычисляется допустимое отклонение, исходя из заданного в поле счетчика справа значения процента;
3. Standard deviation(s) (Стандартное отклонение) - при установке переключателя в данное положение для каждой точки данных вычисляется стандартное отклонение, которое затем умножается на заданное в поле счетчика справа число (коэффициент кратности);
4. Standard error (Стандартная погрешность) - при установке переключателя в данное положение принимается стандартная величина ошибки, постоянная для всех элементов данных;
5. Custom (Пользовательская) - при установке переключателя в это положение вводится произвольный массив значений отклонений в положительную и/или отрицательную сторону (можно ввести ссылки на диапазон ячеек).
Планки погрешностей тоже можно форматировать. Для этого их следует выделить щелчком правой кнопки мыши и выбрать в раскрывшемся контекстном меню команду Format Error Bars (Формат планок погрешностей).
Задание 3. С помощью программы Microsoft Excel на основании данных об объеме выпуска Задания 1 необходимо:
Представить временной ряд в виде графика, построенного с помощью мастера диаграмм. Затем добавить линию тренда, подбирая наиболее подходящий вариант уравнения.
Представить полученные результаты в виде таблицы «Подбор уравнения тренда»:
Таблица «Подбор уравнения тренда»
Представить выбранное уравнение графически, вынеся в график данные о наименовании полученной функции и величину достоверности аппроксимации (R 2).
Задание 4. Ответьте на следующие вопросы:
1. При анализе тренда для некоторого набора данных коэффициент детерминации для линейной модели оказался равен 0,95, для логарифмической - 0,8, а для полинома третьей степени - 0,9636. Какая трендовая модель наиболее адекватна изучаемому процессу:
а) линейная;
б) логарифмическая;
в) полином 3-й степени.
2. По данным, представленным в задании 1, спрогнозируйте объем выпуска продукции в 2003 году. Какая общая тенденция поведения исследуемой величины следует из результатов вашего прогноза:
а) наблюдается спад производства;
б) производство остается на прежнем уровне;
в) наблюдается рост производства.
В данном материале были рассмотрены основные характеристики временного ряда, модели декомпозиции временного ряда, а также основные методы сглаживания ряда - метод скользящего среднего, экспоненциального сглаживания и аналитического выравнивания. Для решения этих задач Microsoft Excel предлагаются такие инструменты, как Moving Average (Скользящее среднее) и Exponential Smoothing (Экспоненциальное сглаживание), которые позволяют сглаживать уровни эмпирического временного ряда, а также команда Add Trendiine (Добавить линию тренда), которая позволяет строить модели тренда и делать прогноз на основе имеющихся значений временного ряда.
P.S. Чтобы включить «Пакет анализ данных», выберите команду Tools →Data Analysis (Сервис → Анализ данных).
Если Data Analysis отсутствует, то необходимо выполнить следующие действия:
1. Выбрать команду Tools → Add-ins (Надстройки).
2. Выбрать в предложенном списке настроек значение Analysis ToolPak (Пакет анализа), а затем щелкнуть ОК. После этого будет выполнена загрузка и подключение к Excel пакета настройки «Анализ данных». Соответствующая команда появится в меню Tools.
©2015-2019 сайт
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-04-27
к.э.н., директор по науке и развитию ЗАО "КИС"
Метод экспоненциального сглаживания
Освоение новых и анализ известных управленческих технологий, которые позволяют повысить эффективность управления бизнесом, становится особенно актуальным для российских предприятий в настоящее время. Один из наиболее популярных инструментов - система бюджетирования, которая базируется на формировании бюджета предприятия с последующим контролем исполнения. Бюджет представляет собой сбалансированные краткосрочные коммерческие, производственные, финансовые и хозяйственные планы развития организации. Бюджет предприятия содержит целевые показатели, которые рассчитываются на основании прогнозных данных. Наиболее значимым прогнозом при составлении бюджета для любого предприятия является прогноз продаж. В предыдущих статьях был проведен анализ аддитивной и мультипликативной модели и рассчитан прогнозный объем продаж на следующие периоды.
При анализе временных рядов использовался метод скользящей средней, в котором все данные независимо от периода их возникновения являются равноправными. Существует другой способ, в котором данным приписываются веса, более поздним данным придается больший вес, чем более ранним.
Метод экспоненциального сглаживания в отличие от метода скользящих средних еще и может быть использован для краткосрочных прогнозов будущей тенденции на один период вперед и автоматически корректирует любой прогноз в свете различий между фактическим и спрогнозированным результатом. Именно поэтому метод обладает явным преимуществом над ранее рассмотренным.
Название метода происходит из того факта, что при его применении получаются экспоненциально взвешенные скользящие средние по всему временному ряду. При экспоненциальном сглаживании учитываются все предшествующие наблюдения - предыдущее учитывается с максимальным весом, предшествующее ему - с несколько меньшим, самое ранее наблюдение влияет на результат с минимальным статистическим весом.
Алгоритм расчета экспоненциально сглаженных значений в любой точке ряда i основан на трех величинах :
фактическое значение Ai в данной точке ряда i,
прогноз в точке ряда Fi
некоторый заранее заданный коэффициент сглаживания W, постоянный по всему ряду.
Новый прогноз можно записать формулой:
Расчет экспоненциально сглаженных значений
При практическом использовании метода экспоненциального сглаживания возникает две проблемы: выбор коэффициента сглаживания (W), который в значительной степени влияет на результаты и определение начального условия (Fi). С одной стороны, для сглаживания случайных отклонений величину нужно уменьшать. С другой стороны, для увеличения веса новых измерений нужно увеличивать.
Хотя, в принципе, W может принимать любые значения из диапазона 0 < W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Выбор коэффициента постоянной сглаживания является субъективным. Аналитики большинства фирм при обработке рядов используют свои традиционные значения W. Так, по опубликованным данным в аналитическом отделе Kodak, традиционно используют значение 0,38, а на фирме Ford Motors - 0,28 или 0,3.
Ручной расчет экспоненциального сглаживания требует крайне большого объема монотонной работы. На примере рассчитаем прогнозный объем на 13 квартал, если имеются данные объема продаж за последние 12 кварталов, используя метод простого экспоненциального сглаживания.
Предположим, что на первый квартал прогноз продаж составил 3. И пусть коэффициент сглаживания W =0,8.
Заполним в таблице третий столбец, подставляя для каждого последующего квартала значение предыдущего по формуле:
Для 2 квартала F2 =0,8*4 (1-0,8)*3 =3,8
Для 3 квартала F3 =0,8*6 (1-0,8)*3,8 =5,6
Аналогично, рассчитывается сглаженное значение для коэффициента 0,5 и 0,33.
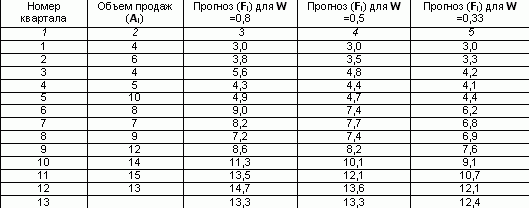
Расчет прогноза
объема
продаж
Прогноз объема продаж при W = 0.8 на 13 квартал составил 13.3 тыс.руб.
Эти данные можно представить в графической форме:

Экспоненциальное сглаживание
Экспоненциальное сглаживание - способ сглаживания временных рядов, вычислительная процедура которого включает обработку всех предыдущих наблюдений, при этом учитывается устаревание информации по мере удаления от прогнозного периода. Иначе говоря, чем "старше" наблюдение, тем меньше оно должно влиять на величину прогнозной оценки. Идея экспоненциального сглаживания состоит в том, что по мере "старения" соответствующим наблюдениям придаются убывающие веса.
Данный метод прогнозирования считается весьма эффективным и падежным. Основные достоинства метода состоят в возможности учета весов исходной информации, в простоте вычислительных операций, в гибкости описания различных динамик процессов. Метод экспоненциального сглаживания дает возможность получить оценку параметров тренда, характеризующих не средний уровень процесса, а тенденцию, сложившуюся к моменту последнего наблюдения. Наибольшее применение метод нашел для реализации среднесрочных прогнозов. Для метода экспоненциального сглаживания основным моментом является выбор параметра сглаживания (сглаживающей константы) и начальных условий.
Простое экспоненциальное сглаживание временных рядов, содержащих тренд, приводит к систематической ошибке, связанной с отставанием сглаженных значений от фактических уровней временного ряда. Для учета тренда в нестационарных рядах применяется специальное двухпараметрическое линейное экспоненциальное сглаживание. В отличие от простого экспоненциального сглаживания с одной сглаживающей константой (параметром) данная процедура сглаживает одновременно случайные возмущения и тренд с использованием двух различных констант (параметров). Двухпараметрический метод сглаживания (метод Хольта) включает два уравнения. Первое предназначено для сглаживания наблюденных значений, а второе -для сглаживания тренда:
где I - 2, 3, 4 - периоды сглаживания; 5, - сглаженная величина на период £; У, - фактическое значение уровня на период 1 5, 1 - сглаженное значение на период Ь-Ьг- сглаженное значение тренда на период 1 - сглаженное значение на период I- 1; А и В - сглаживающие константы (числа между 0 и 1).
Сглаживающие константы А и В характеризуют фактор взвешивания наблюдений. Обычно Л, В < 0,3. Так как (1 - А) < 1, (1 - В) < 1, то они убывают по экспоненциальному закону по мере удаления наблюдения от текущего периода I. Отсюда данная процедура получила название экспоненциально сглаживания.
Уравнение добавляется в общую процедуру для сглаживания тренда. Каждая новая оценка тренда получается как взвешенная сумма разности между последними двумя сглаженными значениями (текущая оценка тренда) и предыдущей сглаженной оценки. Данное уравнение позволяет существенно сократить влияние случайных возмущений на тренд с течением времени.
Прогнозирование с использованием экспоненциального сглаживания подобно процедуре "наивного" прогнозирования, когда прогнозная оценка на завтра полагается равной сегодняшнему значению. В данном случае в качестве прогноза на один период вперед рассматривается сглаженная величина на текущий период плюс текущее сглаженное значение тренда:
Данную процедуру можно использовать для прогнозирования на любое число периодов, на пример на т периодов:
Процедура прогнозирования начинается с того, что сглаженная величина 51 полагается равной первому наблюдению У, т.е. 5, = У,.
Возникает проблема определения начального значения тренда 6]. Существуют два способа оценки Ьх.
Способ 1. Положим Ьх = 0. Такой подход хорошо работает в случае длинного исходного временного ряда. Тогда сглаженный тренд за небольшое число периодов приблизится к фактическому значению тренда.
Способ 2. Можно получить более точную оценку 6, используя первые пять (или более) наблюдений временного ряда. На их основе гю методу наименьших квадратов решается уравнение У(= а + Ь х г. Величина Ь берется в качестве начального значения тренда.





